
FPGAカスタムスーパーコンピューティング
人工知能、最適化、ロボティクス、シミュレーションなどの分野では、計算量の急激な増大が大きな課題となっています。特に生成AIやデジタルツインの発展により、高性能でありながら低消費電力な計算基盤の重要性が高まっています。
私たちの研究室では、回路そのものを用途に応じて再構成できるFPGA(Field Programmable Gate Array)を活用し、「FPGAカスタムスーパーコンピューティング」の研究を推進しています。問題ごとに最適な計算回路を構築することで、従来のCPUやGPUでは実現が難しい高性能・高効率な計算システムを実現します。
AI時代の計算資源問題とFPGAの必要性
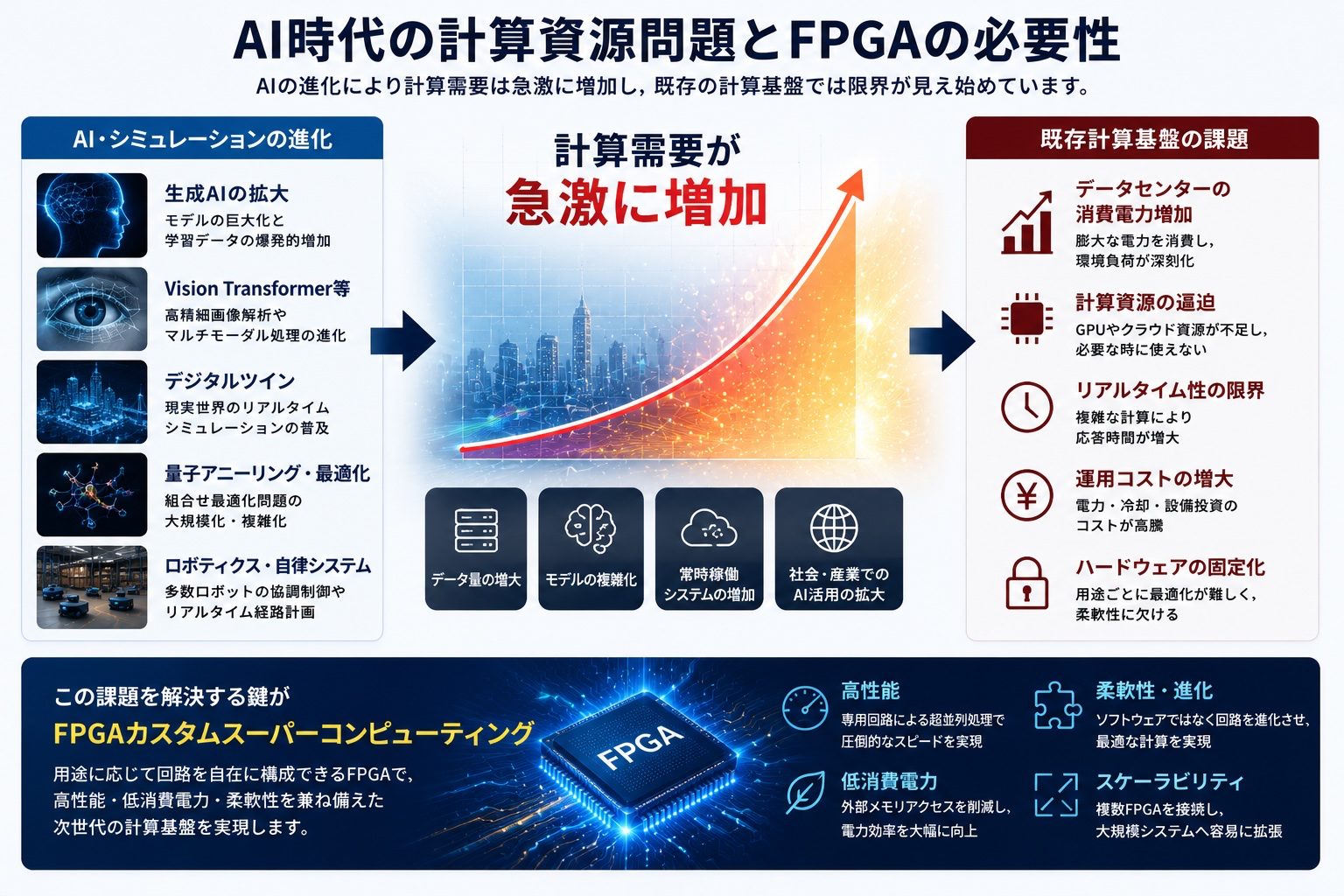
近年、生成AI、大規模言語モデル、Vision Transformer、デジタルツインなどの普及により、計算需要は急激に増加しています。さらに、物流最適化やロボット制御などのリアルタイム処理も高度化しており、膨大な計算資源が必要となっています。
しかし、従来型の計算基盤では、消費電力やメモリアクセスが大きな課題となります。単純にサーバーを増やすだけでは持続可能ではありません。
そこで注目されているのがFPGAです。FPGAは用途に応じて最適な回路を構成できるため、必要な処理だけを効率的に実行し、高性能と低消費電力を両立できます。
FPGAとは
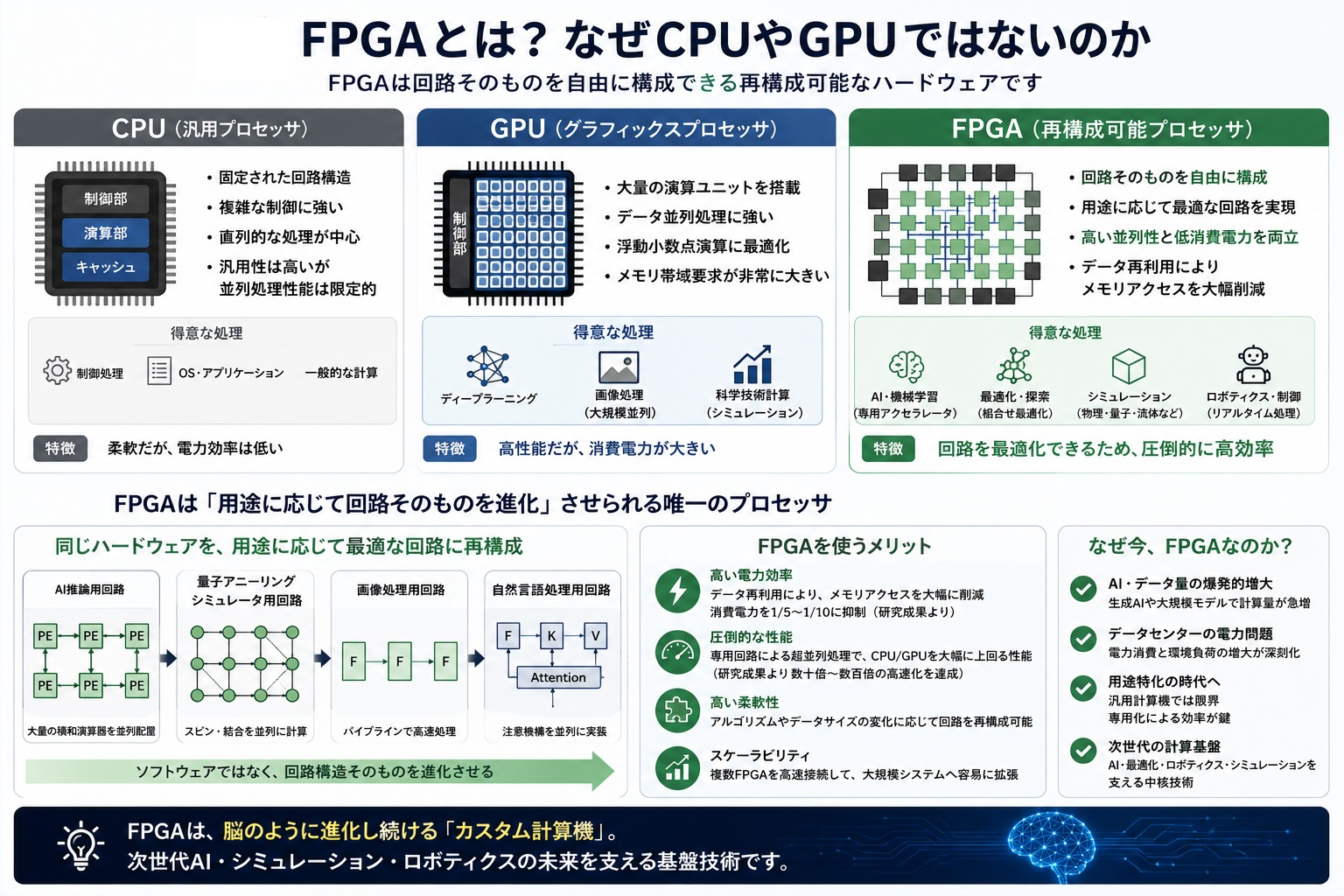
CPUは汎用処理に優れ、GPUは大量並列演算に優れています。一方、FPGAは回路そのものを自由に構成できる再構成可能プロセッサです。
FPGAでは、ソフトウェアを実行するだけではなく、処理内容に合わせて演算回路やデータ転送経路そのものを設計できます。そのため、不要な処理を削減しながら高い性能を発揮できます。
私たちの研究室では、用途に応じて回路構造を進化させることで、高性能・低消費電力な専用計算基盤を実現しています。
次世代AIモデルアクセラレータ
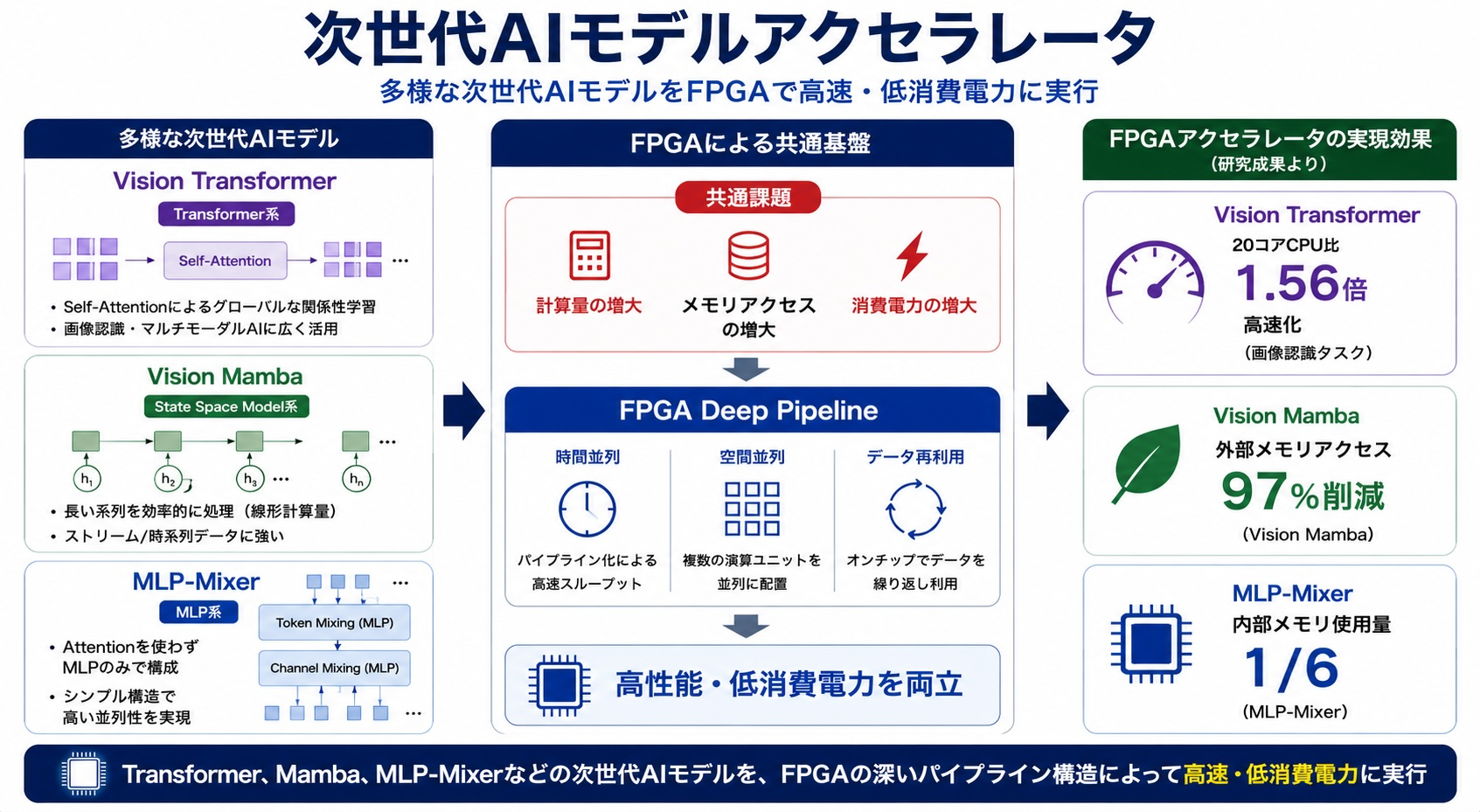
近年のAI研究では、Vision Transformerに代表されるTransformer系モデルに加え、Vision MambaやMLP-Mixerなど新しいアーキテクチャが登場しています。これらのモデルは高い性能を持つ一方で、膨大な計算量とメモリアクセスを必要とします。
私たちは、FPGAの深いパイプライン構造を活用し、時間並列、空間並列、データ再利用を組み合わせたAIアクセラレータを開発しています。
その結果、Vision Transformerでは20コアCPUを上回る性能を実現し、Vision Mambaでは外部メモリアクセスを大幅に削減、MLP-Mixerでは内部メモリ使用量を大きく削減することに成功しています。
FPGAによる量子アニーリングシミュレーション

物流、スケジューリング、配置最適化などの組合せ最適化問題では、候補解の数が爆発的に増加するため、従来手法では計算時間が大きな課題となります。
私たちは、量子アニーリングの探索過程をFPGA上で超並列にシミュレーションすることで、高速かつ低消費電力な最適化システムを実現しています。
FPGA内部では多数のスピン状態を並列に更新し、量子アニーリングの時間発展を高速に再現します。さらに複数のFPGAを接続することで、大規模問題にも対応可能なスケーラブルなシステムを目指しています。
マルチロボット経路最適化
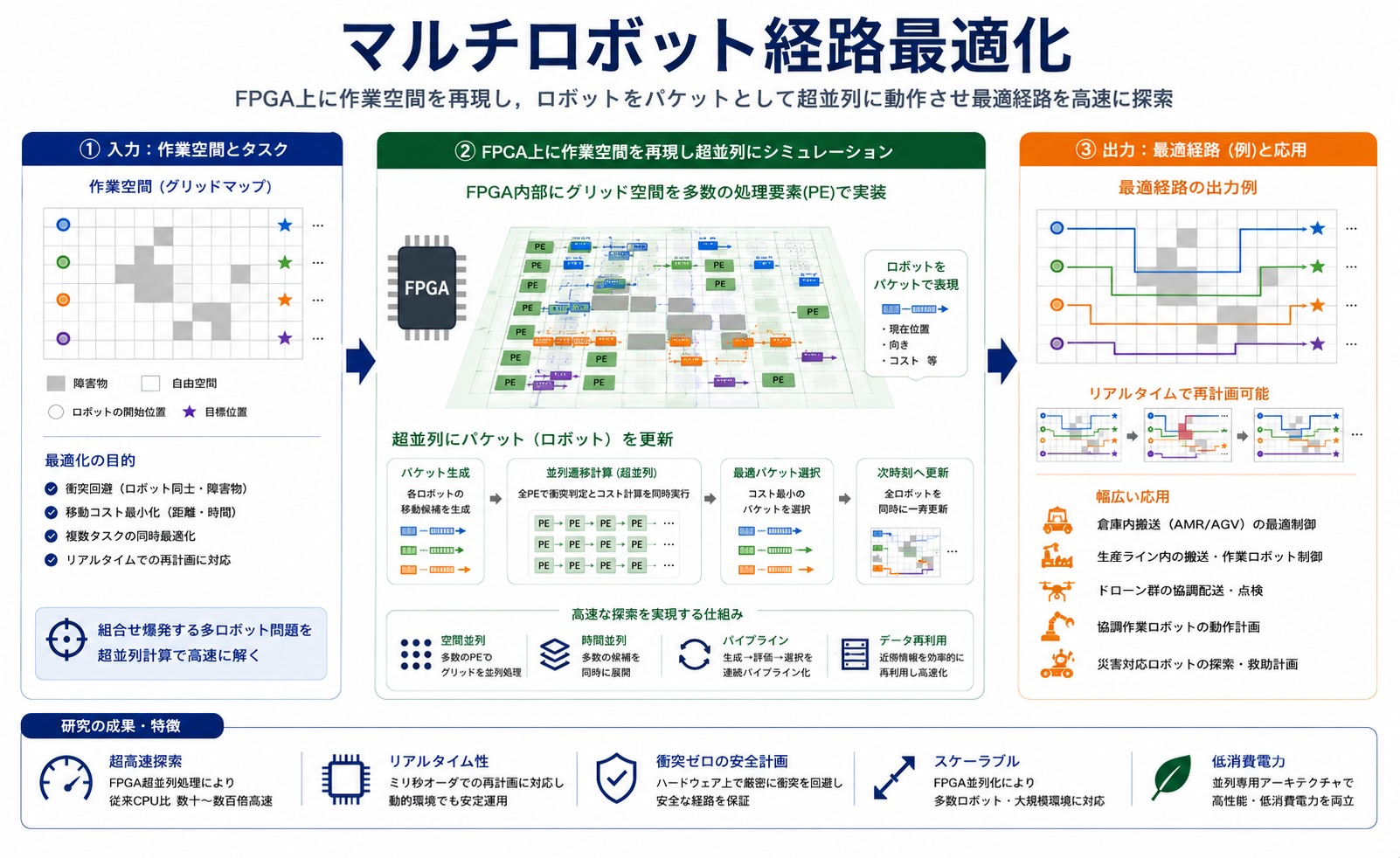
物流倉庫や工場では、多数の搬送ロボットが同時に動作しています。これらのロボットが衝突せず効率的に作業を行うためには、高速な経路計画とリアルタイムな再計画が必要です。
私たちは、Network-on-Chipの考え方を応用し、作業空間そのものをFPGA上に再現する新しいマルチロボットシミュレータを開発しています。
FPGA内部では、ロボットをネットワーク上のパケットとして表現し、多数の処理要素上で超並列に移動をシミュレーションします。これにより、衝突回避、経路最適化、タスク割り当てを高速に実行できます。
将来展望
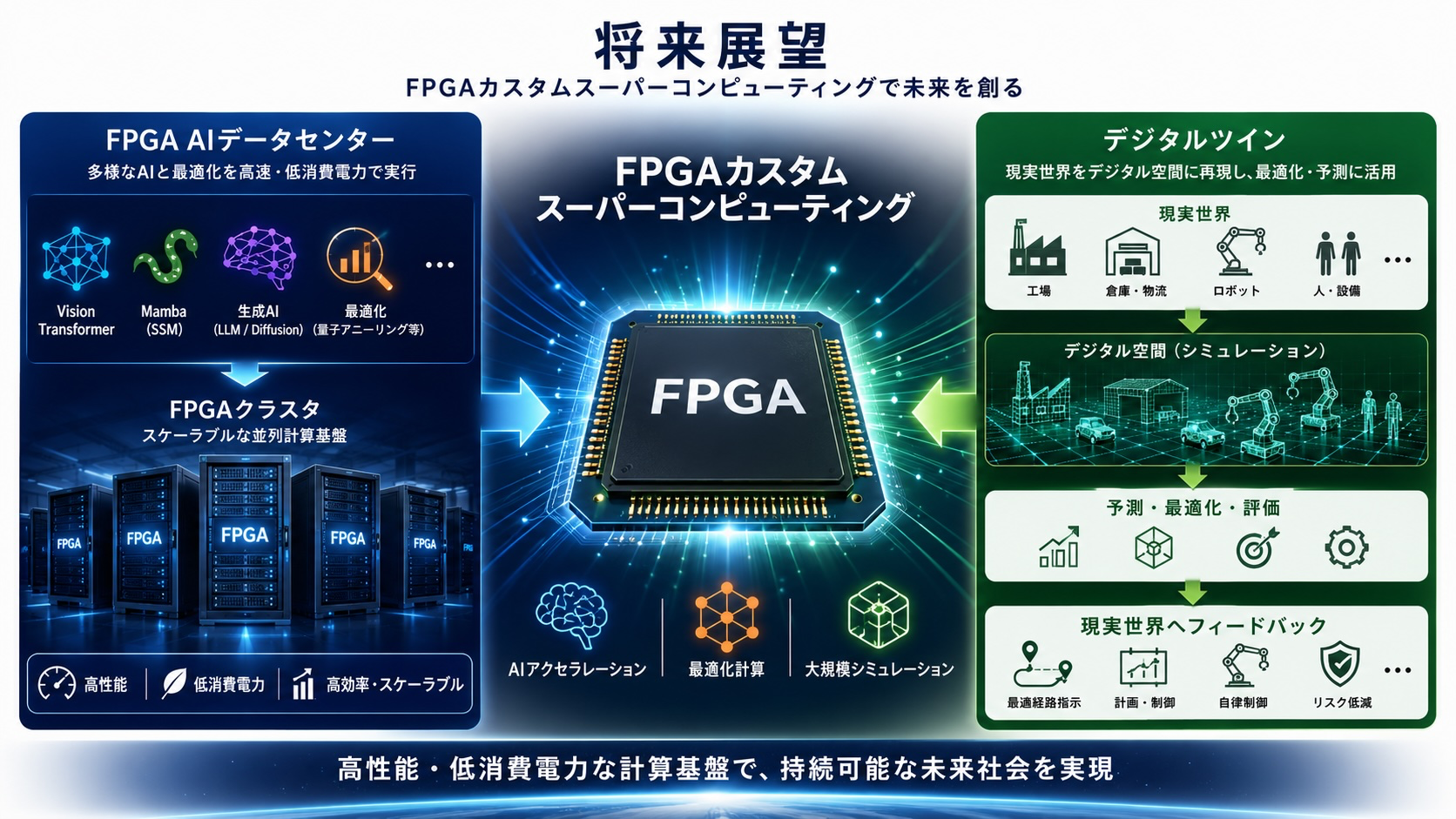
私たちが目指しているのは、個別のアクセラレータ開発に留まりません。AIアクセラレータ、量子アニーリングシミュレータ、マルチロボット最適化技術を統合し、次世代の計算基盤を構築することを目標としています。
将来的には、FPGAクラスタによる高性能・低消費電力なAIデータセンターを実現し、生成AIや最適化計算を効率的に実行できる環境を構築します。
さらに、現実世界を仮想空間上に再現するデジタルツインと連携することで、工場、物流倉庫、ロボットシステム、社会インフラなどをリアルタイムに予測・最適化できる未来を目指しています。
FPGAカスタムスーパーコンピューティングは、AI、最適化、シミュレーションを統合する次世代計算基盤として、持続可能で豊かな未来社会の実現に貢献します。